次世代シーケンサの課題と解決方法
次世代シーケンサ データ解析のポイント
データ解析のポイント
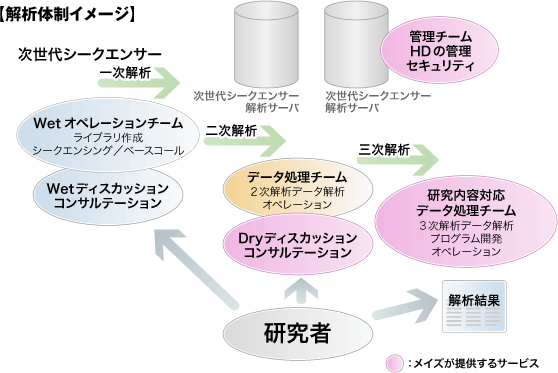
次世代シーケンサがもたらすもの -スクリーニング手法(三次解析)の重要性-
次世代シーケンサによる大量配列解析は、多くの研究者に“手軽で低コストな網羅的解析”の手段を提供することになります。 しかしながら、次世代シーケンサによるアプローチも当然のことながら難しい課題をかかえています・・・続きはここをクリック
次世代シーケンサ普及までの過渡期としての課題
次世代シーケンサ次世代シーケンサが当たり前のように利用されるには、もう2,3年はかかるかもしれません。しかしながら、世界中で次世代シーケンサを使った研究が始まっている中・・・続きはここをクリック
アプリケーションとデータ解析の分類
次世代シーケンサを適用できる分野(アプリケーション)は多岐に渡ります。しかしながら、・・・続きはここをクリック
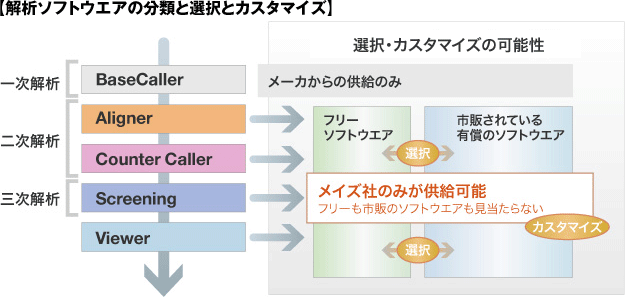
フリーソフトウエアの選択
次世代シーケンサを“測定機械”として利用する場合、通常、シーケンサメーカから提供されているソフトウエアでベースコール(一次解析)し、その配列をAlignerによりマッピング、マッピング情報をもとにシグナル値を出力(二次解析)します・・・続きはここをクリック
解析に利用する公共データの選択
次世代シーケンサのデータ解析では、リファレンスの配列データを使ってマッピングを行ったり、アノテーション情報を利用してスクリーニング処理を行ったりします。転写産物の情報も利用します。しかしながら、 ・・・続きはここをクリック
実験を行う前に、データ解析について、ディスカッションすることの重要性
データ解析において、考慮しなければならない要素が沢山あります。また、それは、測定対象のサンプルや実験のデザインとも関係する場合が多々あります・・・続きはここをクリック
次世代シーケンサがもたらすもの -スクリーニング手法(三次解析)の重要性-
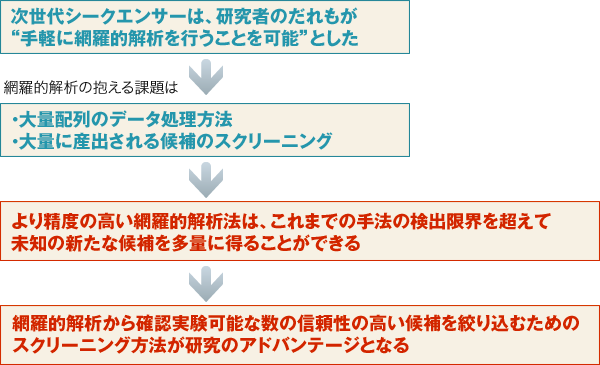
次世代シーケンサによる大量配列解析は、 “手軽で低コストな網羅的解析アプローチ”の機会を多くの研究者に提供することになるのは間違いありません。しかしながら、次世代シーケンサによるアプローチも難しい課題をかかえています。
次世代シーケンサが抱える重要な課題のひとつは、いうまでもなく莫大な配列データを有限時間内で“正しく”処理する方法でありますが、それ以上に重要なことは、網羅的解析方法が抱える、“多量に産出される候補シグナルの絞り込み方法”ではないでしょうか。
新しく開発された網羅的解析技術は、これまでの手法の検出限界を超え、既知の情報では簡単に解釈できない新たな知見を含んだ、大量の候補を産出します。(マイクロアレイが世に出たときそうであったように)よって、大量の候補から、研究の目的に適した信頼性の高い候補を選び出し、次の実験で扱える程度の数に、精度良く絞り込む方法を探ることが重要な課題であり、その方法そのものが研究のアドバンテージになるとわたしどもは考えております。
そこで、我々は、次世代シーケンサを使った“スタンダード”な研究には、パッケージ化された“三次解析”=“スクリーニング”のサービスを提供し、これをカスタマイズすることで研究の独自性に低コストで対応します。さらに、“スタンダード”ではない次世代シーケンサの利用方法や独自のスクリーニング方法をお考えの研究者の方には、オーダメイドのスクリーニング処理構築サービスを提供いたします。
次世代シーケンサ普及までの過渡期としての課題
次世代シーケンサが当たり前のように利用される時代になるには、もう2,3年はかかるかもしれません。しかしながら、世界中で次世代シーケンサを使った研究が始まっている中で、使い方が定まるまで待っていては、重要な研究に遅れを取ることになるのも事実です。この普及までの過渡期である今、この新たな測定手法のデータ処理に関する具体的な課題を列挙してみました。これらの課題について、メイズは当然のことながらまっこうから取り組みます。
【あまり心配しなくても良いかもしれない課題】
- 大量の配列のデータ処理時間は?
- 解析サーバのスペックやコストは?
- ハードディスクの容量は?
- シーケンスの品質は?
- シーケンスの品質チェック方法は?
【まだ明確な回答が得られていない課題】
- ショートリードの配列で“信頼性の高いシグナル”を得られるのか?
- 各シーケンスメーカから解析ソフトウエアが供給され、さらに、世界中でフリーのソフトウエアが争うように開発され、日々、バージョンアップされているが、どのソフトウエアを使えばいいい?
- 高速シーケンスを使った網羅解析から得られる膨大な数の候補を絞り込む方法は?
- 候補を絞り込むスクリーニング処理は、研究目的に依存するためパッケージが世に出ていない?
- 解析サーバはUnixでしかも共用利用だが、運用管理やトラブル対応はどうすればいいのだろう?
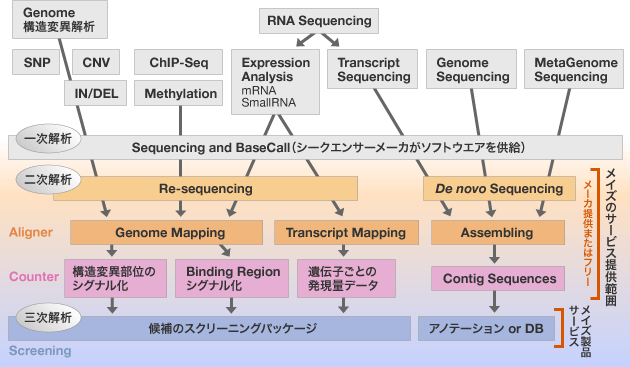
アプリケーションとデータ解析の分類
次世代シーケンサが適用される分野(アプリケーション)は多岐に渡ります。しかしながら、シーケンサは塩基配列を読むことしかできません。また、ゲノムマップやアッセンブルもアプリケーションとの関係はそれほど強くありません。実際にアプリケーションと深く関わるソフトウエアの階層は、二次解析のCallerやCounterと呼ばれる部分とメイズが提供する三次解析=スクリーニングです。
フリーソフトウエアの選択
次世代シーケンサを“測定機械”として利用する場合、通常、シーケンサメーカから提供されているソフトウエアでベースコール(一次解析)し、その配列をAlignerによりマッピング、マッピング情報をもとにシグナル値を出力(二次解析)します。
配列を読む機械ではなく、“測定値”を出力する機械 として、シーケンスから二次解析まで、ハードウエアやソフトウエアによるバイアスを最小限に抑える必要があります。その中で、今現在チューニング可能な階層は、二次解析(AlignerとCaller/Counter)以降のデータ解析です。
二次解析に使われるソフトウエアは、フリーで使えるものが数多くインターネット上に存在します。それらのほとんどが論文化され、また、実際の研究に利用された実績を持っています。
ですので、二次解析用のソフトウエアについては、自ら開発するというよりは、シーケンサメーカが提供するソフトウエア、フリーのソフトウエア、または、有償のソフトウエアから“適切なものを選択して”利用するのが良いと思います。
特に、フリーのソフトウエアは、Openソースで、処理方式が論文になっており、処理内容等がブラックボックスになっていないため、市販の製品よりは、実際の解析に使われているケースが多いようです。
メイズは、NCBIのSRA等の実データを使い、自ら出力結果を確認したフリーソフトウエアをご紹介します。また、まだまだフリーソフトウエア利用の実績が少ないアプリケーションについては、調査を行いディスカッションを重ねて、ソフトウエアの選択をお手伝いします。
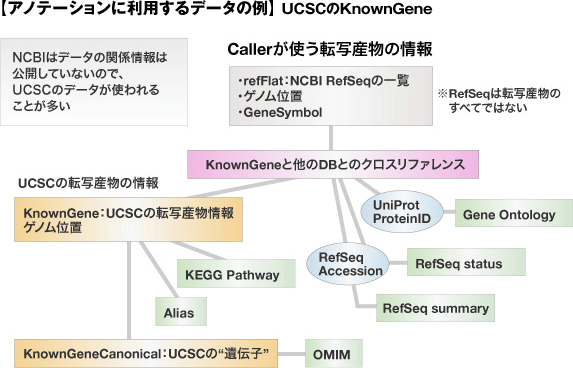
解析に利用する公共データの選択
次世代シーケンサのデータ解析では、リファレンスの配列データを使ってマッピングを行ったり、アノテーション情報を利用してスクリーニング処理を行ったりします。転写産物の情報も利用します。しかしながら、公共DBのデータは、サイトによりそれぞれ特徴があり、研究目的によって、どのサイトのどのデータを利用するかよく検討する必要があります。
弊社では、UCSCにあるNCBIのデータを利用していますが、場合によっては、NCBIではなく該当のプロジェクトのデータ公開サイトの情報を利用することもあります。
たとえば、リファレンスゲノムも、同じストレインのものが手に入るとは限りません。どのストレインのゲノムが一番良いのか等、あらかじめ評価したほうが良いでしょう。
さらに、シーケンスする前にターゲットとする領域を絞り込む際にも、どの情報を利用するのか(RefSeqなのかmRNA&ESTまで広げるのか等々)を検討する必要があります。
実験を行う前に、データ解析について、ディスカッションすることの重要性
データ解析において、考慮しなければならない要素が沢山あります。また、それは、測定対象のサンプルや実験のデザインとも関係する場合が多々あります。ですので、特殊な実験でなくても、事前にデータ解析についてディスカッションしておく必要はあります。ましてや、ノーマルな配列解析ではない実験をお考えの場合は、予備実験等も含めて十分な準備が必要です。もし、ディスカッションにデータ解析の知識と経験を持ったメンバーが必要であれば、お気軽にお声をおかけください。